
Parallel processing with Scala and Akka Actors
Everyone experienced in distributed, and data-intensive systems or big data technologies must have heard about Akka. This article will introduce you to the actor programming model while developing a data processing application exploiting techniques provided by Akka Actors library to build concurrent and parallel systems. This series will skip ” Scala and Akka Basics” parts because official documentation is excellent, and you can create a good foundation of Akka by reading it. This series aims to provide a hands-on introduction to the Akka toolkit.
So, let’s talk about the implementation details. As you guessed, we will use Scala with Akka, which also has full support for Java. We will develop an application to read logs from the file system and count the number of occurrences of HTTP status codes in a given file. All data processing tasks will be executed in parallel. In the actor programming model, the base unit is an actor, and actors asynchronously communicate by sending and receiving messages.
Since our application will be actor-based, let’s look at the actor hierarchy.
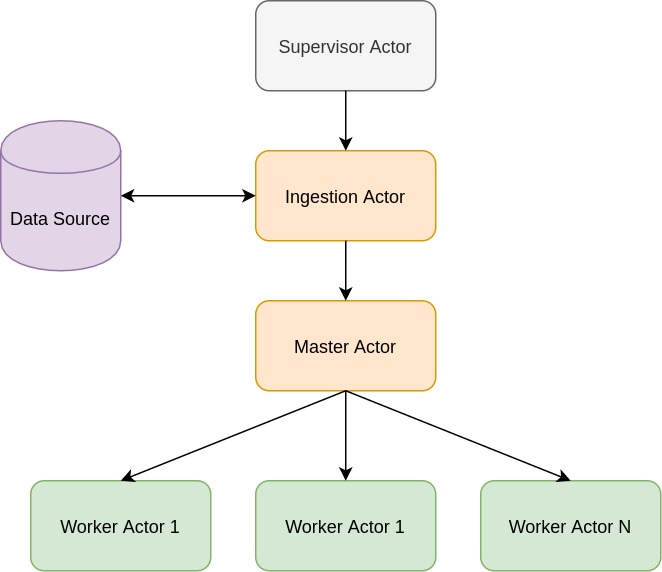
You can see four actor types, Supervisor, Ingestion, Master, and Worker. Names are more or less self-explanatory, but let’s make things clear. Good practice in actor-based programming is to organize actors in a tree-like structure. So the root actor in our application will be Supervisor Actor who will be an entry point in our system.
- Supervisor Actor is responsible for spawning and managing Ingestion Actor.
- Ingestion Actor will be the parent of Master Actor.
- Also, you can notice that we will have multiple Worker Actors, who will do all the heavy lifting, but Master Actor is responsible for their coordination.
To give you more details about the problem we will solve using Akka, let me walk you through the whole data processing flow.
- Dataset of weblogs that we will process can be downloaded from kaggle.
- It’s a CSV file containing IP, Time, URL, Status on every line, but not every line is in a valid form, so we will have to deal with that.
- When Ingestion Actor is initialized, it will try to initialize Master Actor, who will spawn an arbitrary number of Worker Actors. After workers are initialized, Master Actor will notify Ingestion Actor that it’s ready to start processing.
- Ingestion Actor will start reading from a given file line by line, filter only valid ones, and pass it to Master Actor.
- Master Actor will distribute incoming requests from Ingestion Actor to Worker actors in a round-robin fashion.
Finally, let’s review some code.
Applcation entry point
object Application extends App {
implicit val system = ActorSystem("actor-system")
val supervisor = system.actorOf(
Supervisor.props("input", "output", 3), "supervisor"
)
supervisor ! Supervisor.Start
}
Supervisor Actor
object Supervisor {
final object Start
final object Stop
def props(input: String, output: String, parallelism: Int) =
Props(new Supervisor(input, output, parallelism))
}
In a Supervisor Actor companion object, all messages and methods for creating an actor are defined. This pattern should be applied to every actor.
Here is Supervisor Actor implementation:
class Supervisor(input: String,output: String, parallelism: Int)
extends Actor
with ActorLogging {
import Supervisor._
val ingestion: ActorRef = createIngestionActor()
override def receive: Receive = {
case Start =>
ingestion ! Ingestion.StartIngestion
case aggregate @ Master.Aggregate(_) =>
aggregate.result.foreach(println)
case Stop =>
context.system.terminate()
}
}
The Supervisor Actor is simple. He is responsible for starting the whole data processing pipeline, printing results to the console upon receiving it, and stopping the actor system. For the sake of simplicity, I choose to print the results, but in a real scenario, it could be something like writing results to some database, message queue, or filesystem. Also, shutting down the actor system upon finishing all tasks is very important since it is a heavyweight structure that, upon initialization, allocates threads, and to release them, you need to stop the actor system.
Ingestion Actor
Ingestion Actor is responsible for reading a file from a given path, processing it, and passing it to a Master Actor. When the whole file is read, it will notify Master Actor that ingestion is done.
Ingestion Actor companion object implementation:
object Ingestion {
final object StartIngestion
final object StopIngestion
final case class Line(text: String)
def props(input: String, output: String, nWorkers: Int) =
Props(new Ingestion(input, output, nWorkers))
}
I prefer to implement another trait for actors with some additional functionalities, where business logic is concentrated and will be mixed with the actor. This makes the actor class clean and straightforward because we are only dealing with its behavior. Actor behavior is a way of message processing.
trait IngestionHandler {
val ip: Regex = """.*?(\d{1,3})\.(\d{1,3})\.(\d{1,3})\.(\d{1,3}).*""".r
val validIp: String => Boolean = line => ip.matches(line.split(",")(0))
}
Here we have a simple function to validate if the line starts with an IP address or not since we need only those lines that do.
Ingestion Actor implementation:
class Ingestion(input: String, output: String, nWorkers: Int)
extends Actor
with ActorLogging
with IngestionHandler {
import Ingestion._
val master: ActorRef = createMasterActor()
lazy val source = Source.fromFile(createFile())
override def receive: Receive = {
case StartIngestion =>
log.info("Initializing Master Actor...")
master ! Master.Initialize
case Master.MasterInitialized =>
log.info("Starting ingestion...")
source.getLines().filter(validIp).map(Line).foreach(master ! _)
log.info("Collecting results...")
master ! Master.CollectResults
case aggregate @ Master.Aggregate(_) =>
context.parent.forward(aggregate)
self ! StopIngestion
case StopIngestion =>
source.close()
context.parent ! Supervisor.Stop
}
Upon initialization, Master Actor is spawned, and the data source is ready. When MasterInitialized message is received, Ingestion Actor starts to read file line by line, filter only the valid ones, map them into Line case class, and pass it to Master Actor. After the whole file is read, Ingestion Actor demands results from Master Actor. Note that all communication is fully asynchronous. Received results will be forwarded to the parent actor (Supervisor Actor). After that, the file stream is closed, and the parent is notified about that with the message Stop.
Actors Deep Dive
Until now, we learned how to implement simple actors with Scala describing message flow protocol between them and explaining the relationships among actors in the defined actor hierarchy.
The next step is to implement two more actors: Master Actor and Worker Actor. Since Master Actor is the brain of our application and most complex among all actors, because it is responsible for distributing incoming requests to workers and gathering results from them when data processing is finished, we will first implement Worker Actor.
Worker Actor
object Worker {
final object ResultRequest
final case class ResultResponse(id: Int, state: Map[String, Long])
final case class Date(month: String, year: Integer, hour: Integer)
final case class Log(ip: String, date: Date, url: String, status: String)
def props(id: Int) = Props(new Worker(id))
}
Here is some familiar pattern where the first is implemented actors companion object, where message protocol is defined and a factory method that returns actor wrapped in a Props class which is immutable configuration object used for creating new actors through actors system or actor context. If something is not clear in the previous sentence, I recommend reading this page of Akka official documentation.
Now let’s talk about the message protocol. There are four defined messages:
- ResultRequest is a message received by Master Actor, when there is no data left to process, which means, as a name suggests, that worker actor should return aggregated processing results to Master Actor.
- ResultResponse is, as you assumed, a message that contains all data processed by a worker.
- Date and Log case classes are our domain objects constructed from Line message received by Master Actor.
As we are already familiar with a message flow through actors, we know that Line is just a wrapper class around line read from source by Ingestion Actor sent to Master Actor and finally forwarded to one of the Worker Actors. The goal of our application is to count the number of occurrences of HTTP status codes from file reading it line by line. So upon receiving Line, Worker Actor should transform that to Log case class. So here is an implementation of that function:
trait WorkerHandler {
import Worker._
def toLog(line: String): Log = line.split(",").toList match {
case ip :: time :: url :: status :: _ =>
val date = time.substring(1, time.length).split("/").toList match {
case _ :: month :: timeParts :: _ =>
val year = timeParts.split(":")(0).toInt
val hour = timeParts.split(":")(1).toInt
Date(month, year, hour)
}
Log(ip, date, url, status)
}
}
This implementation relies heavily on pattern matching because it allows us to deconstruct case classes and collections. If you want to find out more about pattern matching in Scala or you are not very clear about it, feel free to reach me or read this.
Finally, let’s review Worker Actor implementation:
class Worker(id: Int) extends Actor
with ActorLogging
with WorkerHandler {
import Worker._
type StatusCode = String
type Count = Long
var state: Map[StatusCode, Count] = Map.empty
override def receive: Receive = {
case Ingestion.Line(text) =>
val status = toLog(text).status
state.get(status) match {
case Some(count) =>
state += (status -> (count + 1))
case None =>
state += (status -> 1)
}
case ResultRequest =>
sender() ! ResultResponse(id, state)
}
}
There are only a few lines of code, but to be sure, let’s examine all details.
Starting from the beginning, we could see the state variable where processing results are stored.
var state: Map[StatusCode, Count] = Map.empty
Upon receiving the Line message, Worker Actor transform it to Log and then update the state with the next logic:
state.get(status) match {
case Some(count) =>
state += (status -> (count + 1))
case None =>
state += (status -> 1)
}
Here we have some pattern matching again. Since Map from Scala Collections returns Option[T], we can pattern match against it. If there is some value, we will get Some(value), and if the value is absent, we will get None. To learn more about Option type check this.
And that is a full implementation of a Worker Actors, simple as that. But to improve our actor design, let’s remove the state variable and pass it through behavior, like this:
override def receive: Receive = process(Map.empty)
def process(state: Map[StatusCode, Count]): Receive = {
case Ingestion.Line(text) =>
val status = toLog(text).status
state.get(status) match {
case Some(count) =>
val newState = state + (status -> (count + 1))
context.become(process(newState))
case None =>
val newState = state + (status -> 1)
context.become(process(newState))
}
case ResultRequest =>
sender() ! ResultResponse(id, state)
}
The result of removing a mutable state is an even cleaner and simpler actor.
Master Actor
This is the last chapter of this article where Master Actor implementation will be reviewed.
object Master {
final object Initialize
final object MasterInitialized
final object CollectResults
final case class Aggregate(result: Seq[(String, Long)])
def props(nWorkers: Int) = Props(new Master(nWorkers))
}
Since Master Actor have multiple behaviors, each will be explained separately. Let’s start with the initial behavior.
override def receive: Receive = {
case Initialize =>
log.info(s"Spawning $nWorkers workers...")
val workers: Seq[ActorRef] = (1 to nWorkers).map(createWorker)
context.become(forwardTask(workers, 0))
sender() ! MasterInitialized
}
Initialize message received from Ingestion Actor will trigger the creation of Worker Actors. A number of workers are defined upon creating Master Actor. Here is the implementation of createWorker method:
def createWorker(index: Int): ActorRef =
context.actorOf(Worker.props(index), s"worker-$index")
After workers are initialized, they are ready to start receiving tasks from their parents.
context.become(forwardTask(workers, 0))
This code snippet(above) tells actors how to react to the following message. Actor’s context.become method takes a PartialFunction[Any, Unit] that implements the new message handler.
type Receive = PartialFunction[Any, Unit]
Receive type seen in code is Akka alias for PartialFunction[Any, Unit].
Now, after this is clear, let’s review forwadTask behavior:
def forwardTask(workers: Seq[ActorRef],
currentWorker: Int): Receive = {
case line @ Ingestion.Line(_) =>
val worker = workers(currentWorker)
worker ! line
val nextWorker = (currentWorker + 1) % workers.length
context.become(forwardTask(workers, nextWorker))
case CollectResults =>
workers.foreach(_ ! Worker.ResultRequest)
context.become(collectResults())
}
Master Actor reacts to the two types of messages in this behavior: Line and CollectResults.
When Line is received, we will have access to workers, a collection of all Worker Actors and currentWorker, which is the index of Worker Actor to whom the incoming message will be passed. After the message is sent to the wanted worker, we need to determine the index of the next Worker Actor who will need to receive the following message.
val nextWorker = (currentWorker + 1) % workers.length
context.become(forwardTask(workers, nextWorker))
The first line of code nextWorker index is determined in a round-robin fashion, and the following line is the same as the one we explained before. You can capture the pattern we are using to carry the state via method arguments.
When the CollectResults message is received, we iterate over workers and request results from them. After that, Master Actor behavior is switched to collectResults, when it’s ready to handle responses from all workers.
val results = new ArrayBuffer[Worker.ResultResponse]()
def collectResults(): Receive = {
case response @ Worker.ResultResponse(_, _) =>
results += response
if (results.length == nWorkers) {
context.parent ! toAggregate(results.toSeq)
}
}
Here, we introduced results, which collects all received messages from workers. When all results are collected from workers, we will transform responses to the final result and pass it to the parent(Ingestion Actor), but it’s better to pass these results via behavior like we did it in Worker Actor. The first step is to change how forwardTask handles CollectResults:
case CollectResults => {
workers.foreach(_ ! Worker.ResultRequest)
context.become(collectResults(Seq.empty))
}
Finally, we need to modify the “collectResults” behavior.
def collectResults(agg: Seq[ResultResponse]): Receive = {
case res @ ResultResponse(_, _) if agg.length == (nWorkers - 1) =>
context.parent ! toAggregate(agg +: results)
case res @ ResultResponse(_, _) =>
context.become(collectResults(agg +: results))
}
I first introduced variables because it’s hard to pass the state via behavior for most people at first. It will take some time till you get used to it. I also had a problem fully understand this pattern.
Let’s review the rest of the Master Actors code:
trait MasterHandler {
def toAggregate(results: Seq[Worker.ResultResponse]): Aggregate = {
val aggregate = results
.map(_.state)
.flatMap(_.toList)
.groupBy(_._1)
.map { case (k, v) => k -> v.map(_._2).sum }
.toList
.sortBy(_._2)
Aggregate(aggregate)
}
}
In MasterHandler, a method transforms results to Aggregate case class, which is just a container for a collection of Tuple(String, Long), where the first element of a tuple is a status code. The second one is a count of occurrences.
And finally, we finished our application. Let’s review the whole code for Master Actor:
class Master(nWorkers: Int) extends Actor
with ActorLogging
with MasterHandler {
import Master._
override def receive: Receive = {
case Initialize =>
log.info(s"Spawning $nWorkers workers...")
val workers: Seq[ActorRef] = (1 to nWorkers).map(createWorker)
context.become(forwardTask(workers, 0))
sender() ! MasterInitialized
}
def forwardTask(workers: Seq[ActorRef],
currentWorker: Int): Receive = {
case line @ Ingestion.Line(_) =>
val worker = workers(currentWorker)
worker ! line
val nextWorker = (currentWorker + 1) % workers.length
context.become(forwardTask(workers, nextWorker))
case CollectResults =>
workers.foreach(_ ! Worker.ResultRequest)
context.become(collectResults(Seq.empty))
}
def collectResults(agg: Seq[ResultResponse]): Receive = {
case res @ ResultResponse(_, _) if agg.length == (nWorkers - 1) =>
context.parent ! toAggregate(agg +: results)
case res @ ResultResponse(_, _) =>
context.become(collectResults(agg +: results))
}
def createWorker(index: Int): ActorRef =
context.actorOf(Worker.props(index), s"worker-$index")
}
Summary
You learned how to write a relatively simple application with Akka, design master-worker architecture, and implement a few communication patterns between actors. There is a lot of improvements that can be added to this application. Some of them are to refactor the codebase to use Typed Actors and implement supervision strategies. Check official Akka documentation on Supervision and Monitoring to learn more about it. Another way to improve this application will be to remove Master Actor completely and to use Akka Routers, which can quickly help us to distribute requests among workers without worrying about the implementation of algorithms like round-robin or some else, as we did here for learning.
Here is the source code if you want to play with it or even improve it. Github repository: Data processing with Akka Actors.
Some of these improvements will be a theme for another article.
You can find me at:
Or send me a question to skrbic.alexa@gmail.com